
Tutorials¶
Algorithm Template Docker 🐋¶
- 👉 Please refer to our 🐋 TopBrain_Algo_Submission repo on GitHub as a template and guide on the submission process. (new 🔝🧠 TopBrain version now online!)
- The validation phase is not used for final evaluation.
- Please use validation phase to debug and validate your Docker submission workflow.
- Or better still, test locally with the provided
test_run.shand use theTry-out Algorithmon your algorithm page- Please refer to the
READMEof our submission template repo for more instructions
- Please refer to the
- The final test phases only allow for one submission per team for each phase
- The test phases take much longer than the smaller validation phases to be evaluated (at least 1.5 hours!)
- ⚠️🚨 New change by GC: Submissions to multiple phases in a challenge cannot happen in parallel! This means you have to allocate at least 1.5 hours between your MRA and CTA submissions for final test phases, since they are now blocking each other.
- Please plan ahead and reserve enough time if you submit to both MRA and CTA final test phases.
Lessons from TopCoW 📰¶
We have summarized a few lessons learned from the TopCoW winning algorithms, which could be helpful for solving the more complex TopBrain whole vessel segmentation task:
- Benefits of mixed modality training for CTA
- Training with both MRA and CTA modalities led to better performance for individual modality, particularly for CTA :)
- Importance of topological optimizations
- A wide range of topological optimizations were used by the top submissions, for example:
- Centerline-based loss functions
- Connectivity-based optimizations
- A wide range of topological optimizations were used by the top submissions, for example:
👉 More information can be found in the 📰 TopCoW summary paper's Discussion section.
FAQ¶
0. Common pitfalls in failed submissions¶
- Watch out for
Time limit exceedederrors (try your docker out before submission helps) - During inference, you can first cast/convert the input images to float before inputting them to your model
- this prevents the following RuntimeErrors:
Input type (torch.cuda.ShortTensor) and weight type (torch.cuda.HalfTensor)result type Float can't be cast to the desired output type Short
- this prevents the following RuntimeErrors:
- Container size must be under 10GB ⚠️
- Usable main memory of at most 31 GiB DRAM ⚠️ (1 GB is reserved by GC, so 32 - 1 = 31)
- The
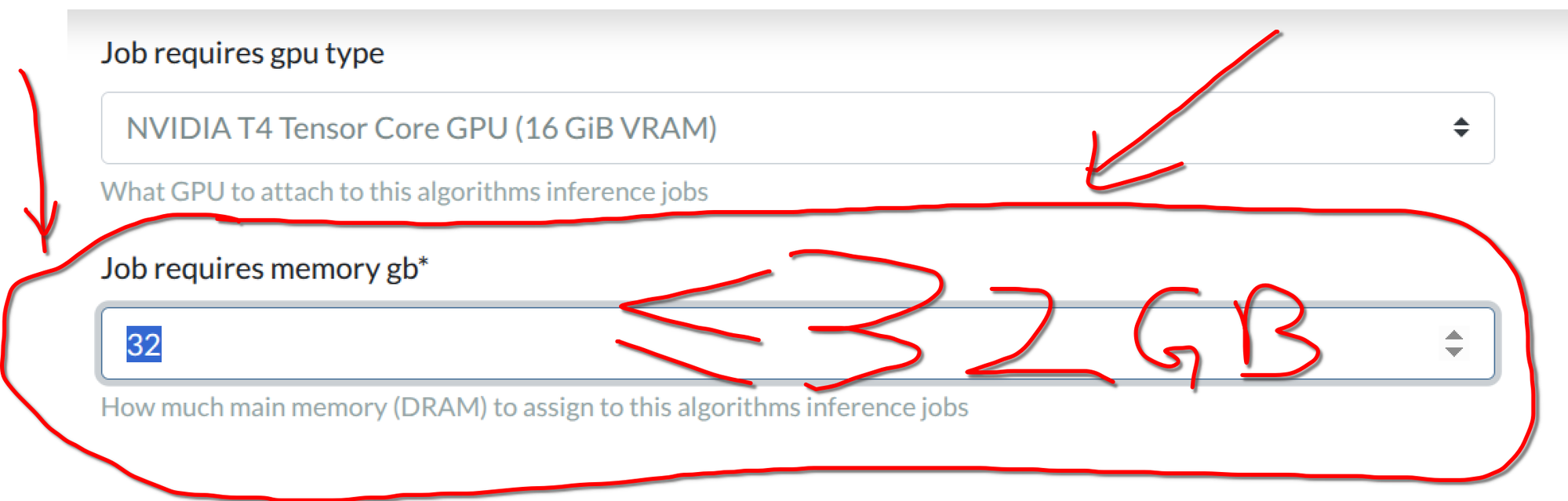
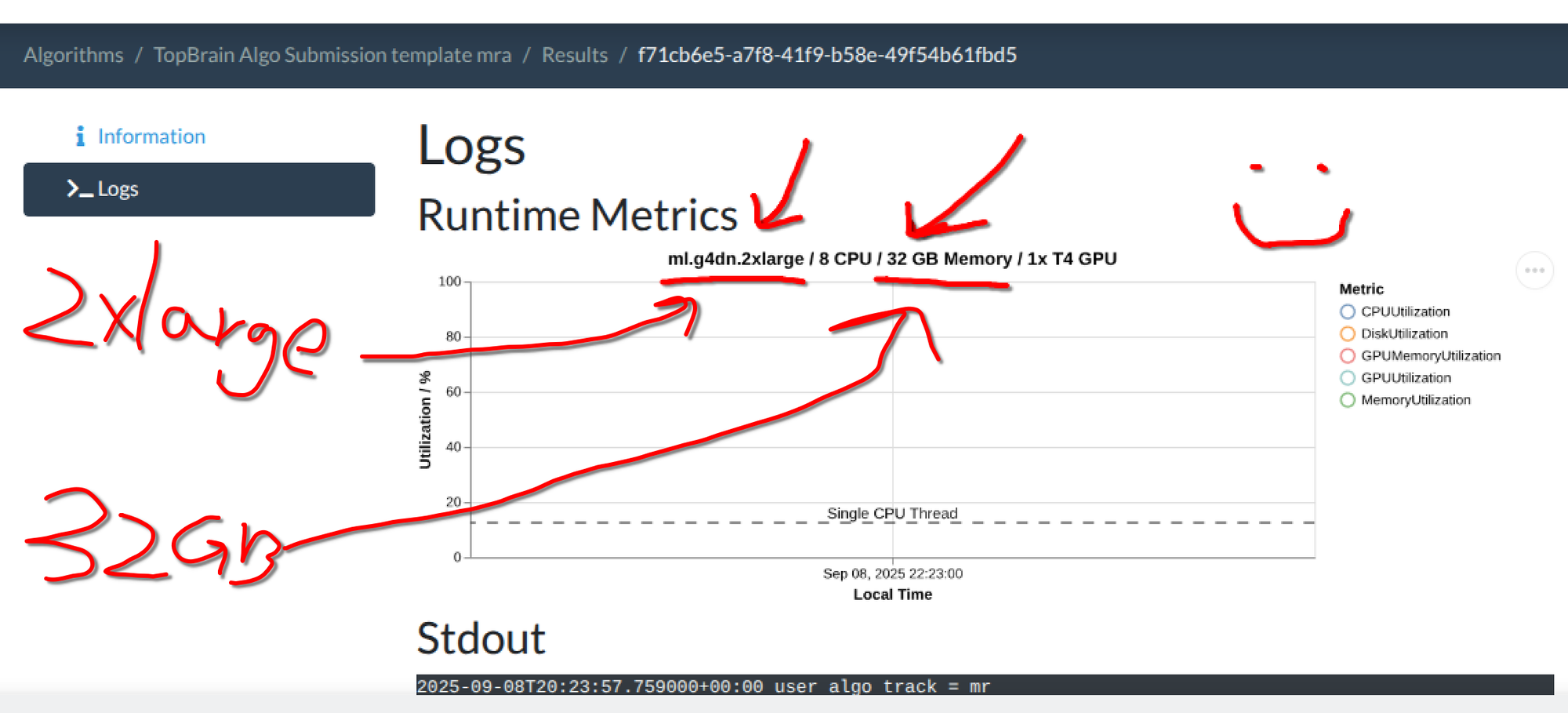
test_run.shin the algorithm template repo simulates this limitation locally. So make sure you test your container with ourtest_run.shfirst! - The default for newly created algorithms is 16GB. New in GC: You need to update the memory setting AFTER algorithm upload! Here are the steps to change the memory used for your algorithm. 1) After you have uploaded the algorithm Docker, go to your algorithm's page and click "Update Settings"; 2) Fill in a number of at most 32 in "Job requires memory gb; 3) 32 GB correspond to the
2xlargeinstance type. (You do not have to adjust the memory if you are okay with the 16GB default.)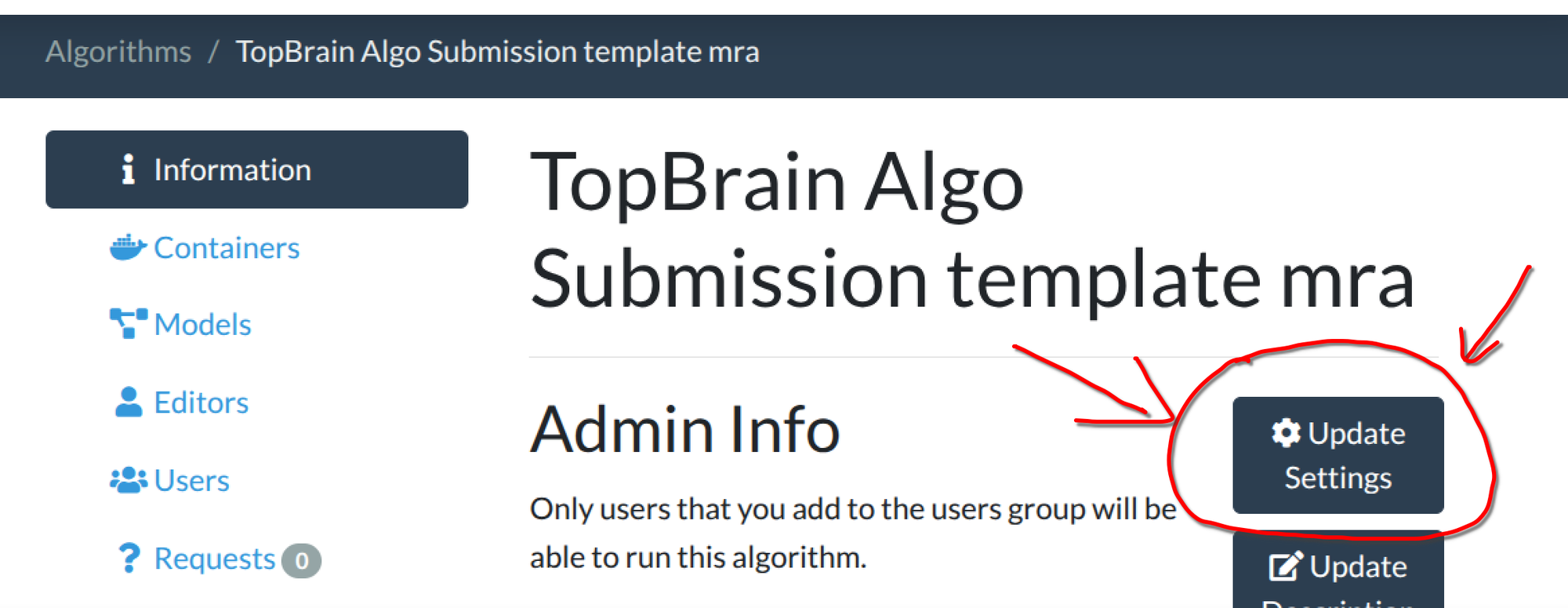
- The
1. How do you weight the metrics and how will the final ranking be done?¶
For the MICCAI in-person event and its results annoucement, we will simply use an equal weighting of metrics mentioned in our "Assessment" page. Please visit our GitHub repo 👉 TopBrain_Eval_Metrics 📐 for our evaluation metrics for the tasks. (We will broadcast in the forum and webpages and github readme accordingly if we update any metrics.)
The ranking to be annouced for the event and awards will thus be based on the leaderboard displayed on grand-challenge. The leaderboard uses equal weights for each column (for example when you see "mean position", it is the mean of several columns' positions/ranks), and 'rank then average'.
We will summarize the results and do post-challenge analysis. Additional metrics and more advanced ranking analysis may be introduced.
2. Can I take part in just one track and one task?¶
Yes, definitely. You are welcome to submit to any track and task of your preference. There are 2 rankings in the end, one for each modality track.
3. Submission Confidentiality and Availability¶
According to grand-challenge, "Challenge organisers do not have access to the algorithms. Challenge organisers only have access to the algorithms logs and predictions for the cases in the challenges test/training archive. Challenge organisers cannot use the algorithm on any other cases. Algorithm owners can see who has access to use their algorithm in the Users tab on their algorithm page. No one is ever given access to the algorithms container image."
Having said that, please contact us with your team's information and contact details, so we can reach out to you for the MICCAI event and follow-up publications. (We organizers cannot see your profile's email due to GDPR.)